

Artificial Intelligence in Trading: A Month of Clarification. arXiv Monthly Review — May 2026.
Algorithmic Token · ENTER Invest · arXiv Monthly Review

May delivered a concentrated theme: artificial intelligence applied to trading systems — as an optimizer, as a portfolio allocator, as an evaluator, and as a source of structural bias. Four papers, one clear thread. The verdict on AI in systematic trading is more nuanced than either the hype or the scepticism suggests.
A Note on the Monthly Review
Each month, on the last week of the month, we scan the quantitative finance corpus on arXiv — primarily from q-fin.TR, q-fin.PM, q-fin.ST, and q-fin.CP, with cross-listings from cs.AI and cs.LG — and select the papers most relevant to practitioners in systematic and algorithmic trading.
Each paper receives a Tradability Score across three dimensions: data access, implementation complexity, and strategy novelty. One paper each month receives fuller treatment as Editor’s Pick.
This month’s theme is unmistakable: every paper selected touches the question of what AI can and cannot do in trading systems. The choice reflects where the research community’s attention was in May 2026 instead of just being a simplified editorial selection.
Editor’s Pick
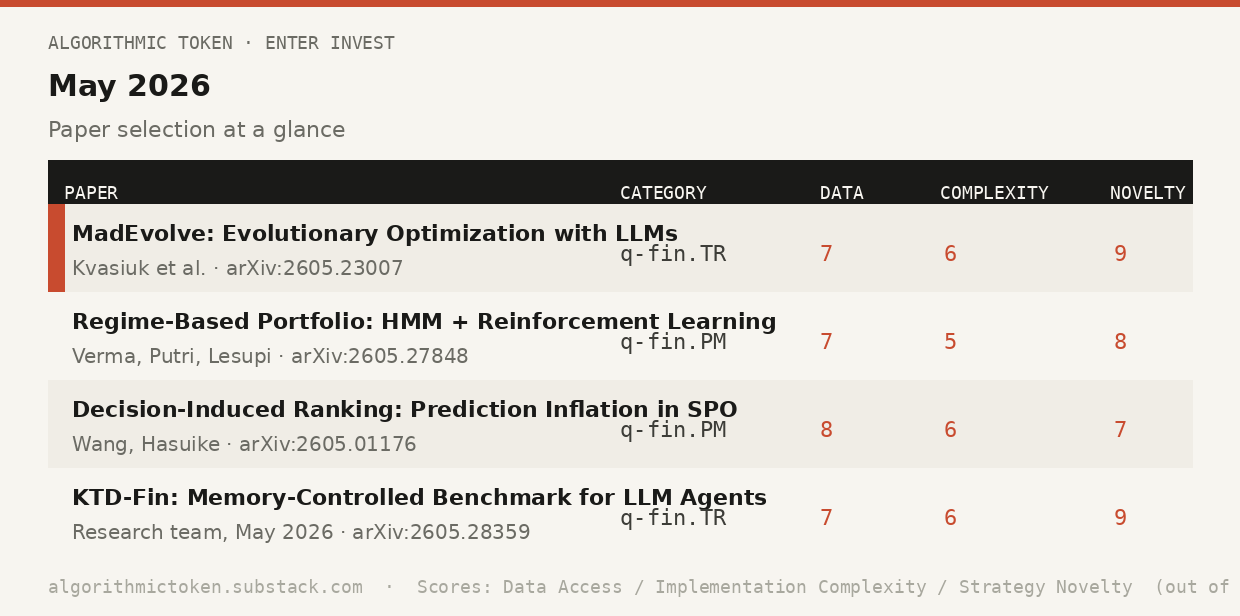
MadEvolve: Evolutionary Optimization of Trading Systems with Large Language Models
Yurii Kvasiuk et al. arXiv:2605.23007 · q-fin.TR · May 21, 2026
This paper asks a different question from most LLM-in-trading research. Rather than asking whether an LLM can trade — a question Strategy Lab #5 addressed rigorously this month, with uncomfortable conclusions — MadEvolve asks whether an LLM can evolve a trading strategy. The distinction matters.
MadEvolve is a general-purpose algorithm optimization framework inspired by DeepMind’s AlphaEvolve, applied here to quantitative finance. The architecture uses LLMs not as decision-makers — not as agents reading news and placing trades — but as mutation operators in an evolutionary search over the space of trading algorithms. The LLM proposes modifications to existing strategy code, those modifications are evaluated against a backtesting objective, and the evolutionary loop selects the best-performing variants for the next generation.
Applied to Bitcoin trading, the framework achieves significant improvements across all tested performance metrics relative to baseline strategies. The paper also explicitly evaluates p-hacking probabilities on the simulation setup — a methodological seriousness that is uncommon and worth noting. The comparison against Claude Code as an agentic search baseline is the most practically interesting result: MadEvolve outperforms single-shot agentic code generation on strategy optimization tasks.
The conceptual contribution is clean: LLMs are poor traders because they conflate memorised market knowledge with reasoning. But LLMs are potentially strong optimizers because the evolutionary objective — improve this code against this backtest — is a well-defined task that does not require market knowledge. The mode of AI engagement with the problem is fundamentally different, and the results reflect that.
Three things practitioners should take from this paper:
First, the evolutionary search framing solves the evaluation problem that KTD-Fin identified. When the LLM is optimizing code rather than making trades, there is no knowledge leakage problem — the LLM never sees market data directly. Second, the p-hacking evaluation is the right question to ask of any evolutionary search framework, and the paper’s explicit treatment of it sets a standard. Third, the Bitcoin application is a proof of concept, not a production system — but the architecture generalizes straightforwardly to equity and futures strategies.
Tradability Score

Runner-Up Papers
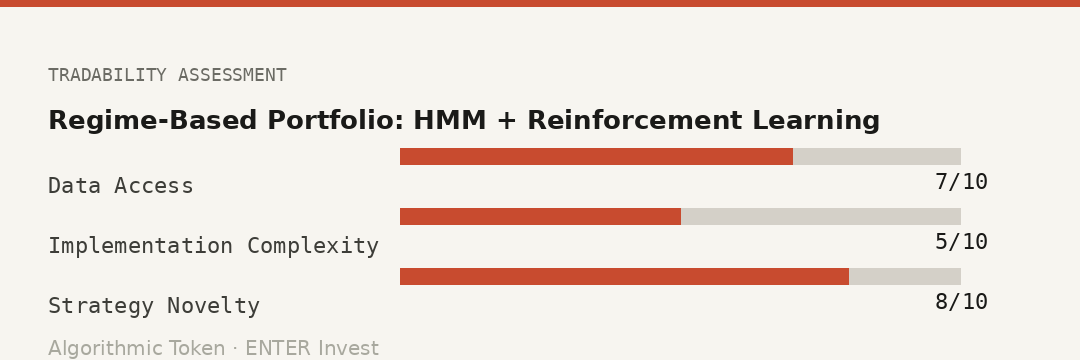
Paper #1 — Regime-Based Portfolio Allocation Using Hidden Markov Models and Reinforcement Learning
Ajay Kumar Verma, Nunik Srikandi Putri, Neo Paul Lesupi arXiv:2605.27848 · q-fin.PM · May 28, 2026
Readers who followed Strategy Labs #3 and #4 will recognize the regime detection thread immediately. This paper combines Hidden Markov Models for regime identification with a Reinforcement Learning agent for portfolio allocation within each identified regime — a two-layer architecture that addresses both the “when to trade” problem (regime classification) and the “how to allocate” problem (RL policy) simultaneously.
The HMM identifies latent market regimes from return and volatility features — bull, bear, and transitional states — and the RL agent learns a separate allocation policy for each regime. The result is a portfolio that is not merely regime-aware in the superficial sense (switching a filter on and off) but genuinely adaptive: the allocation logic itself changes depending on the market environment.
The direct connection to Lab #4’s regime-conditioned ORB framework is worth making explicit. Lab #4 used a simple two-condition boolean gate (elevated vol AND elevated volume). This paper’s HMM regime classifier is a more sophisticated version of the same underlying idea — using market state to condition trading decisions — with the RL allocation layer replacing the fixed ORB signal. Direction 1 from Lab #3 is alive and being actively developed in the academic literature.
Tradability Score
Paper #2 — Decision-Induced Ranking: Prediction Inflation and Excessive Turnover in SPO-Based Portfolio Optimization
Yi Wang, Takashi Hasuike arXiv:2605.01176 · q-fin.PM · May 1, 2026
Predict-then-optimize (SPO) is the dominant paradigm in ML-driven portfolio construction: train a model to predict returns, pass those predictions to an optimizer, execute the optimal portfolio. The problem is well-known in theory but rarely quantified in practice: the optimizer systematically inflates the predictions it receives because assets with larger predicted returns receive larger allocations, which feeds back into the prediction model as apparent confirmation.
Wang and Hasuike call this decision-induced ranking. The optimizer is not a passive recipient of predictions — it actively shapes what gets predicted next, creating a feedback loop that inflates confidence, increases turnover, and degrades out-of-sample performance in ways that are not visible in standard backtests.
The practical implication is direct: any ML-based portfolio system that uses its own trades as training data — which includes most live-deployed RL systems — is vulnerable to this feedback. The paper proposes a debiasing correction and demonstrates reduced turnover and improved out-of-sample Sharpe across the tested universes.
This paper belongs on the reading list alongside Market Structure Lens #1 on transaction costs. Decision-induced ranking is a structural cost that compounds with turnover, and the two effects together can explain the majority of the gap between backtest Sharpe and live Sharpe in ML-driven portfolio systems.
Tradability Score

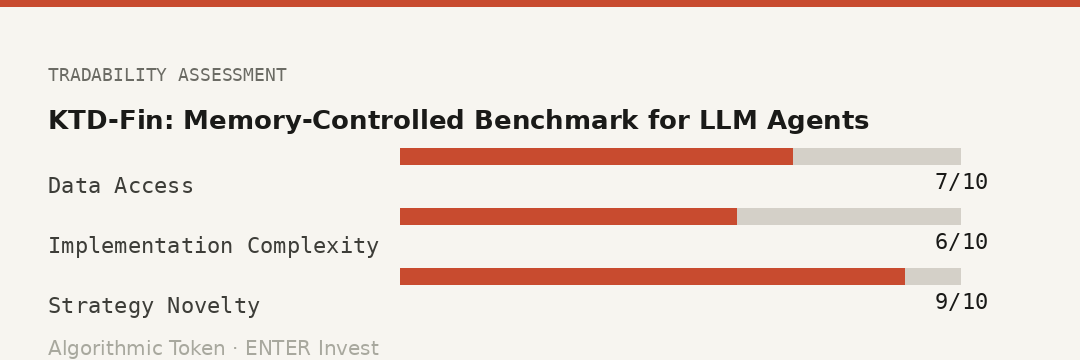
Paper #3 — KTD-Fin: From Knowing to Doing — A Memory-Controlled Benchmark for LLM Trading Agents
[research team, May 2026] arXiv:2605.28359 · q-fin.TR · May 2026
This paper was covered in full as the primary reference for Strategy Lab #5 this month. We include it here for completeness and because its findings are central to the May theme.
The short version: most LLM trading agents research reports results contaminated by knowledge leakage — the model recalling memorised market outcomes rather than performing genuine investment reasoning. Under proper leakage control and Barra-style return attribution, most agents show minimal genuine stock-selection alpha. The cumulative returns reported in standard backtests are largely explained by passive market and style exposure.
Read alongside MadEvolve above: the implication is not that AI is useless in trading, but that the mode of engagement matters. LLMs as traders — failing. LLMs as optimizers of trading code — potentially valuable. The distinction is the month’s central finding.
Tradability Score
This Month in One Paragraph
May 2026 drew a clearer line around artificial intelligence in systematic trading than any single month in recent memory. KTD-Fin falsified the dominant narrative that LLM agents can trade profitably — most of those results were knowledge leakage and beta exposure. MadEvolve reframed the question: LLMs as evolutionary optimizers of trading code show genuine promise precisely because the task does not require market knowledge. Regime-based HMM + RL extended the regime detection thread from our own Labs #3 and #4 into a full portfolio architecture. And Wang and Hasuike quantified the decision-induced ranking problem that corrupts most predict-then-optimise systems. Four papers, one message: AI in trading is real, but the form it takes matters enormously.
What We Are Watching in June
Lab #5 consequences — MadEvolve’s evolutionary optimization framework is a natural candidate for a future Strategy Lab implementation once the Bitcoin proof of concept is extended to futures and equity instruments.
Decision-time leakage — Strategy Lab #6 next week will address this directly, building the one-switch benchmark for detecting look-ahead bias in any backtest.
HMM regime detection — arXiv:2605.27848 points toward a future Market Structure Lens on regime classification methodology, extending Labs #3 and #4’s regime filter into a full probabilistic framework.
Energy and commodity volatility — the rough volatility literature in commodity markets continues to produce preprints relevant to ENTER Invest’s energy trading project; watching for a strong candidate for the June Monthly Review.
Risk Disclosure: The strategies and implementations discussed in Algorithmic Token are experimental and presented for educational and research purposes only. Past performance of any modelled or described strategy is not indicative of future results. All algorithmic trading carries significant financial risk, including the potential total loss of capital. Nothing in this publication constitutes financial advice or an offer to manage investments. ENTER Invest does not manage client funds based on strategies described here unless explicitly and separately contracted to do so. Readers should conduct their own due diligence and consult qualified financial professionals before making any trading or investment decisions.
Next issue: Strategy Lab #6 — Decision-Time Leakage in Financial Backtests: the one-switch benchmark for detecting look-ahead bias.