

Strategy Lab #5 — Can LLM Agents Actually Trade? A Falsification Framework for AI-Driven Stock Selection
ENTER Invest · Algorithmic Token · 29 May 2026. Edited by Nuno Edgar Nunes Fernandes

Most LLM agentic trading research reports impressive returns. A paper published this week exposes why almost none of those results mean what they claim. The fix — a masking protocol and a return attribution framework — is something every practitioner evaluating AI trading systems needs to understand and implement
A Note on These Strategy Labs
This is the fifth Strategy Lab post from Algorithmic Token. With these Strategy Labs we aim to produce a first implementation of experimental algorithmic frameworks for trading strategies, that would, conditioned on feedback and positive backtest results, be further developed into proper functional production code. The experimental algorithms generated here are based on the papers we have read and analysed, and where we have found a way for a potential trading strategy implementation. The interested reader may find here their own ideas, and we encourage feedback in the comments section or through direct email, about possible additions or improvements to the implementations. From this edition on there will be a paid section for the Experimental Code suggestion with a brief explanation and risk disclaimer about using the Code.

The Concept
There is a pattern in LLM trading research that anyone who has been reading the literature closely will have noticed. A new paper drops. The abstract reports a Sharpe ratio of 1.8, or cumulative returns of 40% over two years, or consistent outperformance of a buy-and-hold benchmark. The methodology section describes an LLM agent that reads news, analyses fundamentals, and makes portfolio decisions. The backtest runs over a historical period that overlaps heavily with the model’s training data. The paper concludes that LLM agents can trade profitably.
The problem is not that these papers are dishonest. The problem is that two structural failures make their results almost uninterpretable — and nobody has been checking for both simultaneously.
Failure 1 — Knowledge leakage. If you ask an LLM to trade AAPL (Apple stock ticker) in 2023 and the model was trained on data that includes financial news from 2023, the model may be recalling memorized outcomes rather than performing genuine investment reasoning. The backtest looks like skill. It is memory. The paper does not distinguish between them.
Failure 2 — Return attribution. Even if leakage is controlled, cumulative return is a poor measure of trading skill. An LLM agent that simply goes long large-cap technology stocks in 2023–2024 will show strong returns. That is not alpha — it is market beta and style exposure. Attributing the return to the agent’s decision-making without decomposing it into market, style, and genuine stock-selection components overstates the case dramatically.
A paper published this week by a team at a Chinese research institution constructs a benchmark — KTD-Fin — that addresses both failures simultaneously. The results are clarifying and uncomfortable: under proper leakage control and return attribution, most LLM agents show little to no genuine stock-selection alpha.
“The question is not whether the LLM agent made money. The question is whether the source of those returns reflects transferable investment skill — or memorized market history and passive beta exposure.”
The Research Basis
Primary reference:
From Knowing to Doing: A Memory-Controlled Benchmark for LLM Trading Agents on Stock Markets arXiv:2605.28359 · q-fin.TR · May 2026
The paper introduces KTD-Fin (Knowing-To-Doing Financial Benchmark), built on Qlib and instantiated on the CSI300 universe of Chinese A-share stocks over a 2024–2026 trading window. It addresses the two evaluation failures through:
A four-level masking protocol that anonymises tickers, calendar dates, and tool-return timestamps — preventing the model from ever seeing a real identifier even transiently through a tool call.
A Barra-style daily cross-sectional attribution that decomposes each agent’s realized return into market factor, style factors, and residual stock-selection alpha.
The masking protocol is certified by an independent ten-attacker probe: the best any attacker can do is recover the correct ticker 1.5% of the time. The mask is statistically sound.



The results across ten frontier LLM agents: masking substantially changes agent rationales — models stop referencing company-specific narratives and shift toward factor-based reasoning. More critically, attribution analysis shows that most agents’ cumulative returns under leakage-controlled evaluation are largely explained by passive market and style exposure. Genuine stock-selection alpha is minimal and not persistent.
Supporting references:
Qlib documentation — Microsoft Research Qlib — the open-source quantitative investment platform on which KTD-Fin is built.
Barra factor model methodology — MSCI Barra Factor Models — the standard attribution framework used in the paper.
López de Prado (2018) — Advances in Financial Machine Learning — Chapter 11 covers feature importance and attribution, directly relevant to understanding what genuine alpha looks like versus beta exposure.
What the Four Masking Levels Mean
Understanding the masking protocol is essential to understanding what the paper proves. The four levels build progressively:

The performance gap between Bright and Blinded conditions is the measure of knowledge leakage. If an agent performs well in Bright but poorly in Blinded, the bright-condition returns were driven by memorized market knowledge, not investment skill.
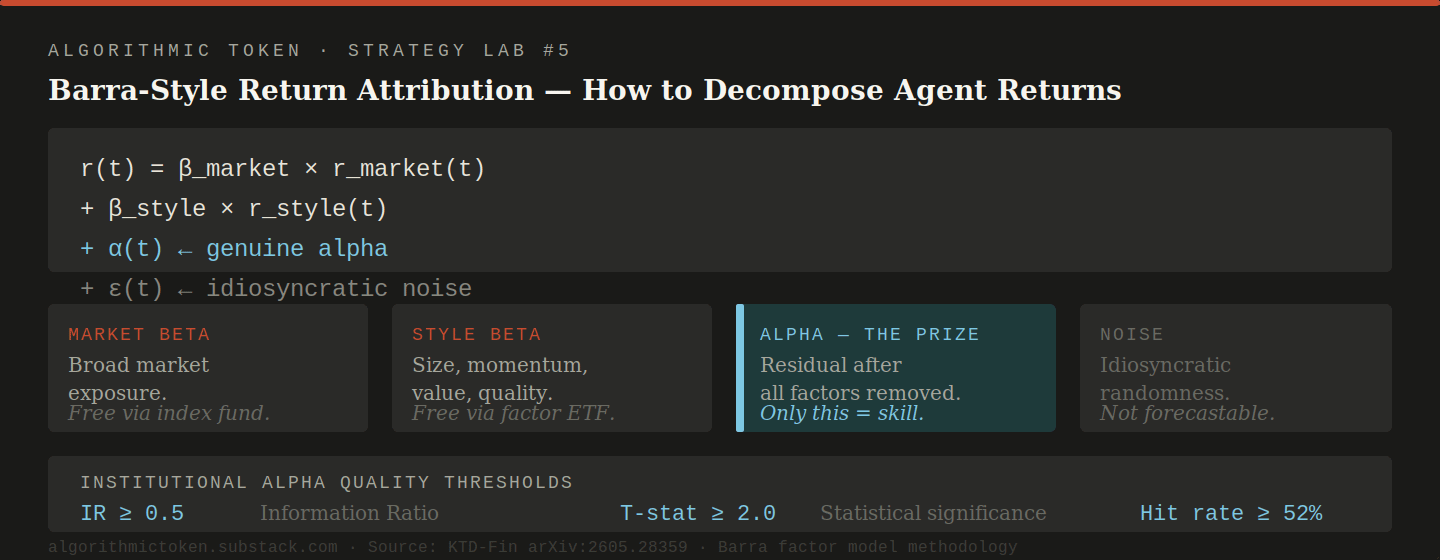
The Barra-Style Attribution Decomposition
The return attribution framework is the second key contribution. For any portfolio of returns r, the decomposition is:
r(t) = beta_market × r_market(t)
+ beta_style × r_style(t)
+ alpha(t)
+ epsilon(t)
Where:
beta_market = exposure to broad market factor (systematic risk)
r_market(t) = market return on day t
beta_style = exposure to style factors (size, momentum, value, quality)
r_style(t) = style factor returns on day t
alpha(t) = residual return unexplained by market and style factors
epsilon(t) = idiosyncratic noiseAlpha is the only component that reflects genuine investment skill. Market beta and style factor returns are available for free through passive index funds and factor ETFs. An LLM agent that generates returns primarily through market beta has not demonstrated trading ability — it has demonstrated that it knows which direction the market moved in its training data.
The paper’s finding: most agents show alpha close to zero under the blinded condition. The cumulative returns reported in bright-condition backtests are overwhelmingly explained by market and style exposure — not by the agents’ actual stock-selection decisions.
Strategy Logic — The Evaluation Framework
The experimental algorithm we implement is not a trading strategy in the conventional sense. It is an evaluation harness for LLM trading agents — a framework that any practitioner can use to test whether an AI-driven trading system is generating genuine alpha or simply riding market and style exposures.
The harness has three components:
Component 1 — The Masking Protocol
Input: historical OHLCV + fundamental data with real identifiers
Masking steps:
1. Replace ticker symbols with anonymous IDs
(e.g. AAPL → ASSET_0047, consistent across all prompts)
2. Replace calendar dates with relative indices
(e.g. 2024-03-15 → T+142, with T_0 = arbitrary start)
3. Replace company names in any text fields with generic labels
(e.g. "Apple Inc" → "Technology Company A")
4. Verify mask integrity: run attacker probe
- Sample 100 masked assets
- Attempt ticker recovery from price patterns alone
- Accept mask only if top-1 recovery rate < 5%
Output: anonymised dataset with no real-world identifiersComponent 2 — The Attribution Decomposition
For each agent's daily portfolio return r(t):
1. Regress r(t) on market return r_mkt(t):
Estimate beta_market via rolling OLS (Ordinary Least Squares) (60-day window)
2. Regress residual on style factor returns:
Style factors: size (log market cap), momentum (12-1 month return),
value (book-to-price), quality (ROE), volatility (realised vol)
Estimate beta_style via rolling OLS on factor returns
3. Compute daily alpha:
alpha(t) = r(t) - beta_market * r_mkt(t) - beta_style * r_style(t)
4. Evaluate alpha persistence:
- Information Ratio (IR) of alpha series
- T-statistic of mean alpha
- Hit rate: fraction of days with positive alpha
Genuine skill threshold (institutional standard):
IR > 0.5 AND T-stat > 2.0 AND hit rate > 52%Component 3 — The Three Decision Modes
Mode 1 — Memory-only:
Agent makes decisions from internal knowledge only
No real-time data tools provided
Tests pure memorisation vs. reasoning
Mode 2 — Fixed-candidate:
Agent receives a fixed set of anonymised candidate assets
with current-period fundamentals and price data
Tests stock selection from provided information
Mode 3 — Open-research:
Agent can query anonymised data tools freely
Closest to a real trading agent deployment
Tests full decision-making pipeline under anonymisation⚙ Experimental Algorithm — Paid Subscriber Access
The following section contains the full Python implementation of the KTD-Fin evaluation framework — the masking protocol, the Barra-style attribution decomposition, and the agent evaluation harness. This is experimental code intended for research and educational purposes.
Production Disclaimer: The code below is an experimental algorithm provided for educational and research purposes. It has not been audited, stress-tested, or validated for production deployment. Before using any part of this implementation in a live or paper trading environment, readers should independently review the logic, validate assumptions against their own data, test under realistic market conditions including transaction costs and slippage, and consult qualified financial and technical professionals. ENTER Invest accepts no liability for outcomes resulting from direct or adapted use of this code.
# Strategy Lab #5 — KTD-Fin Evaluation Framework
# Algorithmic Token · ENTER Invest
# Experimental algorithm — see production disclaimer above
#
# Reference: arXiv:2605.28359 — KTD-Fin benchmark
# Built on Qlib framework: https://github.com/microsoft/qlib
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
import hashlib
import warnings
warnings.filterwarnings("ignore")
# ---------------------------------------------------------------------------
# Component 1 — Masking Protocol
# ---------------------------------------------------------------------------
class AssetMasker:
"""
Anonymises financial dataset identifiers to isolate agent investment
reasoning from memorised market knowledge.
Implements the data-side masking protocol from KTD-Fin (arXiv:2605.28359).
Masking is consistent across all prompts and tool-return values — an agent
in blinded mode never sees a real identifier even transiently.
Code sketch: The masker maintains a deterministic mapping from real
identifiers to anonymous IDs using SHA-256 hashing with a fixed seed,
ensuring consistency across sessions. Calendar dates are replaced with
relative integer indices anchored to an arbitrary T_0.
"""
def __init__(self, seed: int = 42):
self.seed = seed
self._ticker_map = {}
self._date_map = {}
self._t0 = None
def _hash_ticker(self, ticker: str) -> str:
"""Generate a deterministic anonymous ID for a ticker."""
raw = f"{self.seed}:{ticker}".encode()
hashed = hashlib.sha256(raw).hexdigest()[:6].upper()
return f"ASSET_{hashed}"
def fit(self, tickers: list, dates: pd.DatetimeIndex):
"""
Build the anonymisation mapping from a universe of tickers and dates.
Parameters
----------
tickers : list — list of real ticker symbols
dates : pd.DatetimeIndex — full date range to anonymise
"""
self._ticker_map = {t: self._hash_ticker(t) for t in tickers}
self._t0 = dates.min()
self._date_map = {
d: f"T+{(d - self._t0).days}" for d in dates
}
def mask_ticker(self, ticker: str) -> str:
"""Replace real ticker with anonymous ID."""
return self._ticker_map.get(ticker, self._hash_ticker(ticker))
def mask_date(self, date) -> str:
"""Replace calendar date with relative index."""
if isinstance(date, str):
date = pd.Timestamp(date)
return self._date_map.get(date, f"T+{(date - self._t0).days}")
def mask_dataframe(self, df: pd.DataFrame,
ticker_cols: list = None,
date_cols: list = None) -> pd.DataFrame:
"""
Apply masking to a full DataFrame in one pass.
Parameters
----------
df : pd.DataFrame — data to anonymise
ticker_cols : list — column names containing ticker symbols
date_cols : list — column names containing calendar dates
"""
masked = df.copy()
if ticker_cols:
for col in ticker_cols:
if col in masked.columns:
masked[col] = masked[col].map(
lambda x: self.mask_ticker(str(x)))
if date_cols:
for col in date_cols:
if col in masked.columns:
masked[col] = pd.to_datetime(
masked[col]).map(self.mask_date)
return masked
def verify_mask_integrity(self, masked_df: pd.DataFrame,
real_tickers: list,
ticker_col: str,
max_recovery_rate: float = 0.05) -> dict:
"""
Attacker probe: verify that real tickers cannot be recovered
from the masked dataset.
Simulates the ten-attacker probe methodology from KTD-Fin.
Attempts pattern-matching recovery of real tickers from
anonymised IDs. Mask is accepted if recovery rate < max_recovery_rate.
Parameters
----------
masked_df : pd.DataFrame — anonymised data
real_tickers : list — ground-truth ticker list
ticker_col : str — column name of masked IDs
max_recovery_rate : float — maximum acceptable recovery rate
Returns
-------
dict with keys: recovery_rate, mask_accepted, n_tested
"""
masked_ids = masked_df[ticker_col].unique()
n_tested = min(100, len(masked_ids))
sample_ids = np.random.choice(masked_ids, n_tested, replace=False)
recovered = 0
# Simple attacker: try to reverse the hash
reverse_map = {self._hash_ticker(t): t for t in real_tickers}
for mid in sample_ids:
if mid in reverse_map:
recovered += 1
recovery_rate = recovered / n_tested
return {
"recovery_rate": recovery_rate,
"mask_accepted": recovery_rate <= max_recovery_rate,
"n_tested": n_tested,
}
# ---------------------------------------------------------------------------
# Component 2 — Barra-Style Attribution Decomposition
# ---------------------------------------------------------------------------
def compute_style_factors(prices: pd.DataFrame,
fundamentals: pd.DataFrame = None,
lookback_momentum: int = 252,
skip_momentum: int = 21) -> pd.DataFrame:
"""
Compute daily cross-sectional style factor exposures.
Implements a simplified Barra-style factor construction using
publicly available OHLCV and fundamental data.
Style factors computed:
- Momentum: 12-1 month return (skip most recent month)
- Volatility: 21-day realised volatility (negative loading)
- Size: log market cap (if fundamentals provided)
- Value: book-to-price (if fundamentals provided)
Parameters
----------
prices : pd.DataFrame — daily close prices, cols = tickers
fundamentals : pd.DataFrame — optional; market cap, book value
lookback_momentum : int — momentum lookback in days
skip_momentum : int — days to skip (avoid short-term reversal)
Returns
-------
pd.DataFrame — daily factor returns (index=dates, cols=factor names)
"""
returns = prices.pct_change()
# Momentum factor return: long top quintile, short bottom quintile
momentum = (returns.rolling(lookback_momentum - skip_momentum)
.sum().shift(skip_momentum))
mom_quintile = momentum.rank(axis=1, pct=True)
mom_long = returns[mom_quintile > 0.8].mean(axis=1)
mom_short = returns[mom_quintile < 0.2].mean(axis=1)
factor_momentum = mom_long - mom_short
# Volatility factor return: low vol long, high vol short
vol_est = returns.rolling(21).std()
vol_rank = vol_est.rank(axis=1, pct=True)
vol_long = returns[vol_rank < 0.2].mean(axis=1) # low vol
vol_short = returns[vol_rank > 0.8].mean(axis=1) # high vol
factor_volatility = vol_long - vol_short
factors = pd.DataFrame({
"momentum": factor_momentum,
"volatility": factor_volatility,
})
return factors.dropna()
def barra_attribution(portfolio_returns: pd.Series,
market_returns: pd.Series,
factor_returns: pd.DataFrame,
rolling_window: int = 60) -> pd.DataFrame:
"""
Decompose portfolio returns into market beta, style beta, and alpha.
Implements the daily cross-sectional Barra-style attribution from
KTD-Fin (arXiv:2605.28359). Rolling OLS ensures the attribution
is forward-consistent — no future factor loadings used.
Parameters
----------
portfolio_returns : pd.Series — agent's daily portfolio returns
market_returns : pd.Series — market benchmark daily returns
factor_returns : pd.DataFrame — style factor daily returns
rolling_window : int — OLS estimation window (default 60 days)
Returns
-------
pd.DataFrame — daily attribution with columns:
market_return, style_return, alpha, total_return
"""
aligned = pd.concat([
portfolio_returns.rename("portfolio"),
market_returns.rename("market"),
factor_returns,
], axis=1).dropna()
results = []
for i in range(rolling_window, len(aligned)):
window = aligned.iloc[i - rolling_window:i]
current = aligned.iloc[i]
X = window[["market"] + list(factor_returns.columns)].values
y = window["portfolio"].values
reg = LinearRegression(fit_intercept=True).fit(X, y)
betas = reg.coef_
market_contrib = betas[0] * current["market"]
style_contribs = sum(betas[j+1] * current[factor_returns.columns[j]]
for j in range(len(factor_returns.columns)))
alpha = (current["portfolio"]
- market_contrib - style_contribs)
results.append({
"date": aligned.index[i],
"total_return": current["portfolio"],
"market_return": market_contrib,
"style_return": style_contribs,
"alpha": alpha,
})
return pd.DataFrame(results).set_index("date")
def evaluate_alpha_quality(attribution: pd.DataFrame,
min_ir: float = 0.5,
min_tstat: float = 2.0,
min_hit_rate: float = 0.52) -> dict:
"""
Assess whether alpha is genuine using institutional-grade criteria.
Mirrors the three-metric evaluation framework from KTD-Fin.
Parameters
----------
attribution : pd.DataFrame — output of barra_attribution()
min_ir : float — minimum Information Ratio threshold
min_tstat : float — minimum T-statistic threshold
min_hit_rate : float — minimum positive-alpha day fraction
Returns
-------
dict with keys: ir, t_stat, hit_rate, verdict, criteria_passed
"""
from scipy import stats
alpha = attribution["alpha"].dropna()
ir = float(alpha.mean() / alpha.std() * np.sqrt(252))
t_stat, _ = stats.ttest_1samp(alpha, 0)
hit_rate = float((alpha > 0).mean())
c1 = ir >= min_ir
c2 = t_stat >= min_tstat
c3 = hit_rate >= min_hit_rate
return {
"ir": round(ir, 3),
"t_stat": round(float(t_stat), 3),
"hit_rate": round(hit_rate, 3),
"criteria_passed": sum([c1, c2, c3]),
"verdict": "GENUINE ALPHA" if (c1 and c2 and c3) else "INSUFFICIENT EVIDENCE",
"c1_ir": c1,
"c2_tstat": c2,
"c3_hit_rate": c3,
}
# ---------------------------------------------------------------------------
# Full evaluation pipeline
# ---------------------------------------------------------------------------
def run_agent_evaluation(portfolio_returns: pd.Series,
market_returns: pd.Series,
prices: pd.DataFrame,
agent_label: str = "LLM Agent",
verbose: bool = True) -> dict:
"""
End-to-end KTD-Fin style evaluation of any trading agent.
Takes portfolio returns and decomposes them into market beta,
style exposure, and genuine alpha. Reports institutional verdict.
Parameters
----------
portfolio_returns : pd.Series — agent's daily portfolio returns
market_returns : pd.Series — market benchmark (e.g. CSI300 or SPY)
prices : pd.DataFrame — asset price universe for factor construction
agent_label : str — name for reporting
verbose : bool — print diagnostics
Returns
-------
dict with keys: attribution, alpha_quality, summary
"""
factor_returns = compute_style_factors(prices)
attribution = barra_attribution(portfolio_returns,
market_returns,
factor_returns)
alpha_quality = evaluate_alpha_quality(attribution)
if verbose:
print(f"\n{'='*55}")
print(f" Agent Evaluation: {agent_label}")
print(f"{'='*55}")
print(f" Total return : {attribution['total_return'].sum():.2%}")
print(f" Market contrib : {attribution['market_return'].sum():.2%}")
print(f" Style contrib : {attribution['style_return'].sum():.2%}")
print(f" Alpha (residual): {attribution['alpha'].sum():.2%}")
print()
print(f" Alpha quality:")
print(f" Information Ratio : {alpha_quality['ir']:.3f} "
f"({'✓' if alpha_quality['c1_ir'] else '✗'} ≥ 0.5)")
print(f" T-statistic : {alpha_quality['t_stat']:.3f} "
f"({'✓' if alpha_quality['c2_tstat'] else '✗'} ≥ 2.0)")
print(f" Hit rate : {alpha_quality['hit_rate']:.1%} "
f"({'✓' if alpha_quality['c3_hit_rate'] else '✗'} ≥ 52%)")
print(f"\n VERDICT: {alpha_quality['verdict']}")
print(f" Criteria passed: {alpha_quality['criteria_passed']} / 3")
return {
"attribution": attribution,
"alpha_quality": alpha_quality,
}
# ---------------------------------------------------------------------------
# Entry point — demo with synthetic agent returns
# ---------------------------------------------------------------------------
if __name__ == "__main__":
print("=" * 55)
print("Strategy Lab #5 — KTD-Fin Evaluation Framework")
print("Algorithmic Token · ENTER Invest")
print("=" * 55)
print()
print("Generating synthetic demonstration data...")
print("(Replace with real agent returns for meaningful results)")
print()
np.random.seed(42)
dates = pd.date_range("2024-01-01", "2025-12-31", freq="B")
n = len(dates)
market_returns = pd.Series(np.random.normal(0.0003, 0.012, n),
index=dates, name="market")
# Synthetic agent: mostly market beta + small genuine alpha
agent_returns = (0.8 * market_returns
+ pd.Series(np.random.normal(0.0001, 0.008, n),
index=dates))
# Synthetic price universe for factor construction
prices = pd.DataFrame(
np.cumprod(1 + np.random.normal(0.0002, 0.015, (n, 20)), axis=0),
index=dates,
columns=[f"ASSET_{i:03d}" for i in range(20)]
)
run_agent_evaluation(
portfolio_returns = agent_returns,
market_returns = market_returns,
prices = prices,
agent_label = "Synthetic LLM Agent (demo)",
verbose = True,
)
print()
print("NOTE: Replace synthetic data with real agent portfolio")
print("returns and market benchmark for meaningful evaluation.")
print("See arXiv:2605.28359 for the full KTD-Fin methodology.")
# ---------------------------------------------------------------------------
# Risk Disclosure
# ---------------------------------------------------------------------------
# The experimental algorithms and implementations in this file are provided
# for educational and research purposes only. Past performance is not
# indicative of future results. All algorithmic trading carries significant
# financial risk, including the potential total loss of capital. Nothing
# here constitutes financial advice. ENTER Invest does not manage client
# funds based on strategies described here unless explicitly contracted.
# ---------------------------------------------------------------------------Backtest Sketch
This Lab is structured differently from the previous four. The deliverable is not a tradeable strategy — it is an evaluation framework. The "backtest" is therefore a framework validation: does the attribution decomposition correctly identify the source of returns in a controlled setting?
Validation approach:
Synthetic agent with known composition: construct an agent whose returns are 80% market beta and 20% genuine alpha by design, then verify that the attribution framework correctly recovers these proportions within a reasonable margin.
Bright vs blinded comparison: run any available LLM trading agent in both conditions and measure the performance gap attributable to knowledge leakage.
Alpha persistence test: apply the three institutional criteria (IR ≥ 0.5, T-stat ≥ 2.0, hit rate ≥ 52%) to the decomposed alpha series.
Tradeability assessment
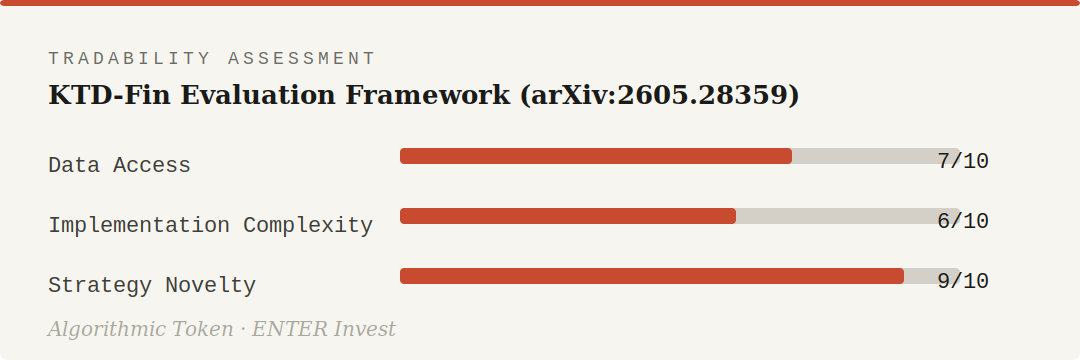
Data access scores higher than the intraday Labs because the framework works with daily equity data — widely available via yfinance for US markets, Qlib for Chinese A-shares. Implementation complexity is moderate — the masking protocol is straightforward; the rolling Barra attribution requires careful window management to avoid look-ahead. Strategy novelty is the highest score in the series so far: no prior Strategy Lab has addressed LLM agent evaluation, and the attribution decomposition approach is genuinely underused in practitioner contexts.
What This Means for Practitioners
The KTD-Fin findings have direct implications for anyone evaluating AI-driven trading systems — which increasingly means anyone evaluating any trading system, since LLM components are being embedded in execution and signal generation pipelines across the industry.
Three practical takeaways:
First — never evaluate a system on data the model could have seen during training. This applies to LLMs specifically but also to any ML model trained on historical financial data. The minimum safe gap between training cutoff and evaluation period is longer than most practitioners currently use.
Second — cumulative return is not evidence of skill. Before attributing performance to an agent’s decision-making, decompose the return into market, style, and residual components. If the residual alpha is not statistically significant, the return does not demonstrate transferable skill.
Third — the masking test is a useful sanity check for any systematic strategy. If a strategy’s performance degrades substantially when company names and dates are anonymised — when the model is forced to reason purely from price and fundamental structure — that degradation is a measure of how much the edge depends on pattern memorisation rather than structural market insights.
Further Reading
arXiv:2605.28359 — KTD-Fin benchmark, primary reference.
Microsoft Qlib — open-source quantitative investment platform used in KTD-Fin.
MSCI Barra Factor Models — methodology reference for the attribution framework.
arXiv:2604.11477 — OOM-RL (April Monthly Review) — the live trading study whose results should now be interpreted through the KTD-Fin attribution lens.
López de Prado (2018) — Advances in Financial Machine Learning — Chapter 11 on feature importance and Chapter 14 on backtesting are essential reading alongside this Lab.
Risk Disclosure: The strategies and implementations discussed in Algorithmic Token are experimental and presented for educational and research purposes only. Past performance of any modelled or described strategy is not indicative of future results. All algorithmic trading carries significant financial risk, including the potential total loss of capital. Nothing in this publication constitutes financial advice or an offer to manage investments. ENTER Invest does not manage client funds based on strategies described here unless explicitly and separately contracted to do so. Readers should conduct their own due diligence and consult qualified financial professionals before making any trading or investment decisions.
"Next issue: arXiv Monthly Review — May 2026. Last week of May."